Robot that reads documents: regular OCR vs machine learning OCR

Damian Zachwieja
10 min of reading
Manual work with documents is a practice from a previous era, and surprisingly it still occurs in many companies, even in corporations. Reading scans with the use of OCR can assure up to 99% accuracy and a lot of saved time. However, this technology is divided into old and new, and their capabilities are completely different. Find out why.
Digital transformation cannot exist without the OCR technology
Since the Big Data boom in 2013, Optical Character Recognition has been adopted as a tool to accelerate not only the collection of business data from contracts, invoices, but also their processing and translation. Since OCR reads documents with an efficiency of 85-99% and has the ability to support 120 languages, every company that has dozens of pages attempts to implement it. Therefore, it is used by banks, accounting offices, as well as research companies and factories.
Despite the development of this technology since the 1970s, its suppliers' promises are perfect only theoretically. Without the use of machine learning in the project with a dedicated OCR solution, the effects of scanning with the basic software are severely limited.
OCR conditional working
As with a corporate server, an administrator who creates document templates is needed to process data with the use of OCR. Thanks to which, the program is able to capture specific information from scanned images. In the case of solutions for consumers, the user learns from a thick manual how to set everything up so that the program finds an address, VAT number or a signature. If the scans are of good quality and the documents are as simple as a receipt, the efficiency is magical. However, OCR is not self-sufficient and will not interpret badly formatted data without our help. For "dynamic teams", the uphill task begins here:
- Documents must be perfectly lit - not too bright, not too dark.
- Each minimal change to the template requires manual modification of the software settings
- Most often, the scan results have to be checked manually in order to eliminate the typos and grammar errors.
- Pages to be analyzed must be exactly vertical, because OCR does not catch text printed at a different angle.
- The text must be of the same size and preferably in one type of font.

Image 1. Upper half - the rest of the text must be entered manually. In the bill on the left, OCR did not recognize the full name of the counterparty, the order quantity and the tax on the price due to the scan being too bright. The right side shows problems with reading words that are surrounded by a non-standard color.
The need to use generally available OCR solutions cannot be overcome. Besides, no one wants to rewrite the whole content as it was with homework in elementary school. The possibilities end as the number of documents that need to be processed increase. However, the problem with reading data and checking the results under a magnifying glass is not the end. Subscription plans get money from entrepreneurs by limiting the number of pages that can be read. After exceeding the sample sum of 200 pages, you need to pay for each additional one. This practice resembles the data limit in mobile operators' packages.
But what about companies where at least 100 pages daily need to be processed?
The process of accepting returns with OCR analysis
Companies in the early stages of digital transformation use OCR linearly. The tool does not take the overload of work from workers, but speeds some of the tasks. Let’s learn the process of collecting return forms in an online store with the help of "consumer" OCR (such as Microsoft Word for a scanner).

Image 2: Consumer OCR software has not changed for many years because implementation of innovative technology for the largest vendors is an unnecessary waste of money. The sample document accounting process won't be different for many companies - unless someone is actually listening to their CTO.
Without digitalisation of the process, time savings can be minimal such as it happens when consumers return handwritten forms. Their regular OCR system is not able to read them. If they send back the document supplemented on the computer, we will read it with satisfactory efficiency only when a printout is clean and the same text size. More rules need to be created.
You can hire two new analysts and make three out of one funnel. But hiring costs absorb funds that employers want to allocate to jobs that directly increase revenue. In this case, implementation of machine learning OCR can be one of the most sensible investments that can reduce operating expenses and save hundreds of hours of manual work.
Facilitation of same processes with machine learning
The definition of machine learning does not need to be learned by heart to understand its potential. With its use, Tesla's car is able travel on autopilot most of the 1,456 km of the route from New York to Atlanta and still be carefully responding to the other objects on the road. However, for machine learning to work, you need studying material. Users struggling with the annoying anti-spam tool reCaptcha helped Google create OCR for reading books (Google Books) and objects on the road (Street View). You could say that they changed the world.
The same model of intelligent analysis science is used to accelerate the digitization of data. The OCR technology combined with machine learning will cope with reading problems thanks to the program that automatically turns the page, removes noise, sharpens text and recognizes letters of different sizes. Automating data reading helps to skip the stages of manual work that previously consumed time that can be measured in money. The administrator no longer needs to check the scan of each page. If the software does not report an error, the information is successfully copied according to established rules. The accuracy of reading information increases over time, because with each correction submitted by the operator, the machine learning algorithm learns to work better.
According to the case studies we found, the benefits of introducing machine learning OCR turn out to be incomparable:
- The Cognizant client that works for real estate developers saved $ 1M on data processing with 99.5% reading efficiency.
- The company that works with Zerone reduced the cost of analyzing every single invoice by 50%.
- In a similar way, Volvo reduced the time that it takes to post an invoice by 40%.
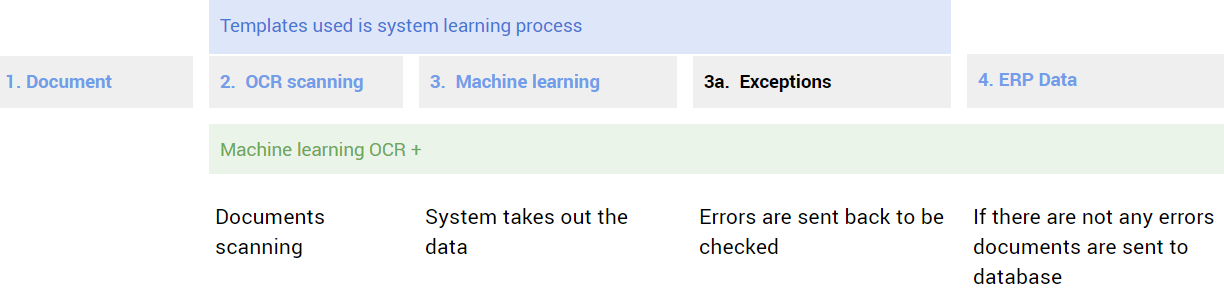
Image 3: Even though machine learning does not offer 100% automation, the self-learning algorithm minimizes the need to verify documents with an accuracy of up to 99% in a short time. Instead of checking each scan, the employee only needs to review the few documents in which errors were found. At the same time, the collected text does not need to be rewritten, because it will be sent to the previously set program.
The three above-mentioned companies need to process more than 1,000 documents per month. Access to data for the people outside of the department was a recurring requirement. Consumer OCR software often does not allow data to be uploaded to the company's document flow system. However, this is not a disadvantage, but a deliberate restriction that reduces the supplier's investment. Data can be copied or exported, but it's still a tedious job. Customized machine learning OCR software leaves the door open. Processed data can be forwarded with most communication channels without the need for human involvement. This allows you to automate email reports, display results on dashboards in the office or to supplement sales trends in the CRM software.
Which option is one to be chosen?
Enterprises that have not implemented OCR due to their passion for manual work, should calculate the total document processing time. There is no way that the use of consumer OCR is not profitable. Due to the uncomplicated operation and extensive help section that most programs have, deployment can take even less than a month. Trial versions allow you to check the usefulness of such a tool for free for a period of 7 to 14 days.
Machine learning OCR works perfectly if entering data manually turns out to be consuming and the number of documents increases each month. Such a project changes the work of all people, becoming a real killer of wasted time - a sacred tool of each department. The implementation is usually done by software houses, which are able to calculate the estimated savings based on the monthly number of processed documents.
According to the Billentis report from 2018, 60-80% of invoices are submitted on paper. Does your company effectively use OCR for document processing?


